這篇文章以繪畫這個垂直領域為切入點,介紹下 aigc 能如何優化當前的繪畫工作流。以此來啟發一下在當下時間點中,另一個與我距離較遠的行業中,aigc 已經能做到什麼,可能帶來新的什麼,我們又能做些什麼。
簡單原理#
下面以我的理解,以擴散模型(Diffusion)為例,簡單說一下它的原理。
訓練過程
我們對原本的圖片加噪點,讓圖片逐漸變成純噪點圖;再讓 AI 學習這個過程的逆過程,也就是如何從一張噪點圖得到一張有信息的高清圖。之後再用條件(比如描述文字或者圖片)去控制這個過程,讓他知道什麼條件該怎麼迭代去噪,生成特定的圖形。
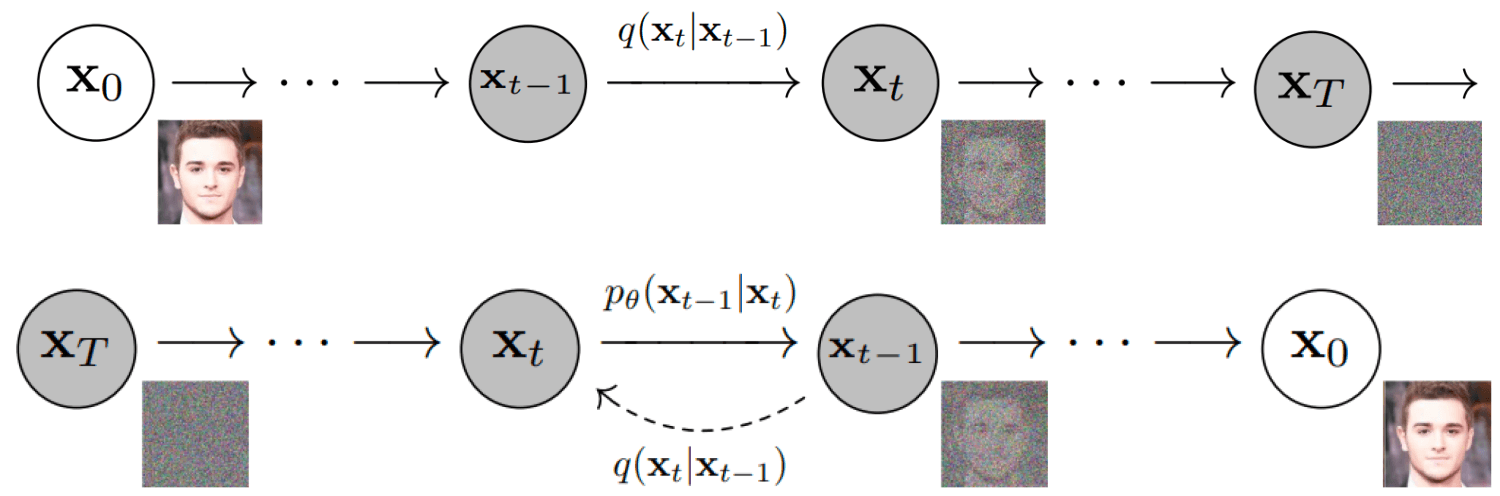
潛在空間(latent space)
一張 512x512 分辨率的圖片,就是一組 512 * 512 * 3 的數字,如果直接對圖片進行學習,相當於 AI 要處理 786432 維的數據,這對算力、計算機性能要求很高。所以我們需要將信息壓縮,壓縮後的空間稱為「潛在空間」。
如果我們有 10000 個人的信息列表,想去找兩個可能是兄弟的人,如果我們遍歷每行處理,那處理的量就有 10000。但如果有這樣一個三維坐標系,代表人的潛在空間,三個軸分別為身高、體重、生日,我們在這個三維空間中找兩個相鄰的點,那麼這兩個相鄰的點代表的人就會有較大的概率是相似的,這樣多維的信息對 ai 來講處理起來更得心應手。
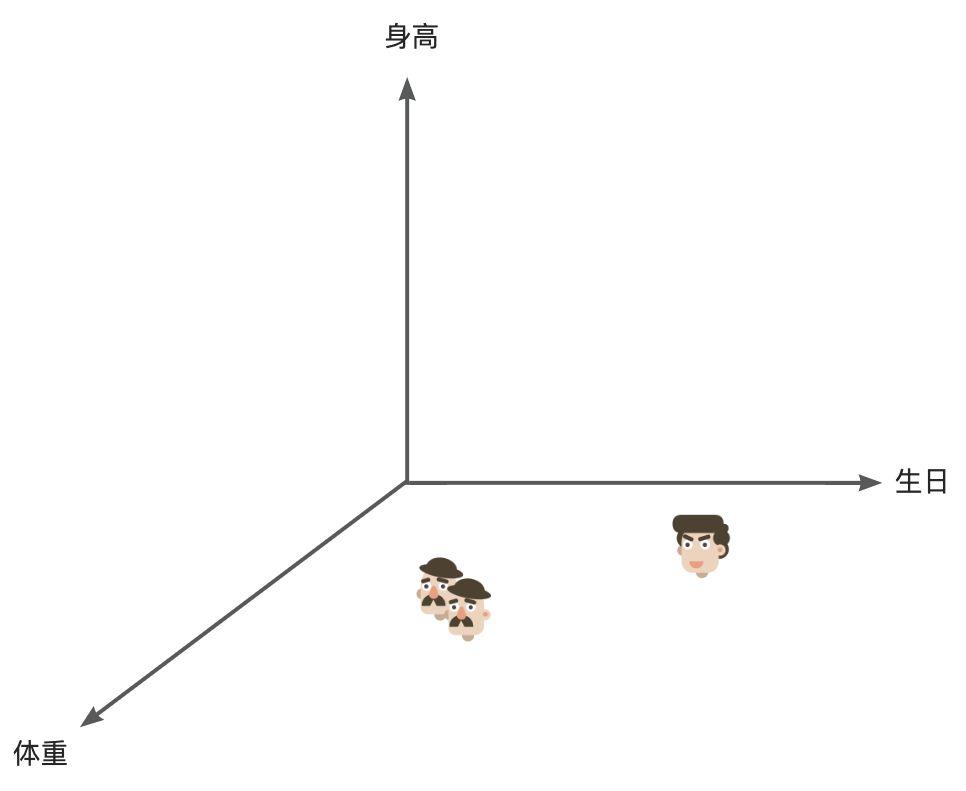
人的認知其實也會這樣,認識一類新事物時,會下意識的去進行特徵歸類,進行多維度的打標。比如我們能很輕易的分辨椅子和桌子不是同類,因為我們在體積這個維度上,他們是明顯不同的。
ai 也能做到同樣的事情,將本來十分龐大的數據集壓縮為很多特徵維度,變為體積小得多的「潛在空間」,於是尋找一張圖片就是像在這樣一個空間裡去找一個對應的坐標點,然後將這個坐標點通過一系列處理轉化為圖片。
CLIP
我們在使用各種線上的 aigc 服務時,經常會用到由文生圖功能。為了建立文字與圖片之前的聯繫,需要 AI 在海量「文本 - 圖片」數據上學習圖片和文本的匹配。這就是 CLIP(Contrastive Language-Image Pre-Training / 對比式語言 - 文字預訓練)所做的事情。
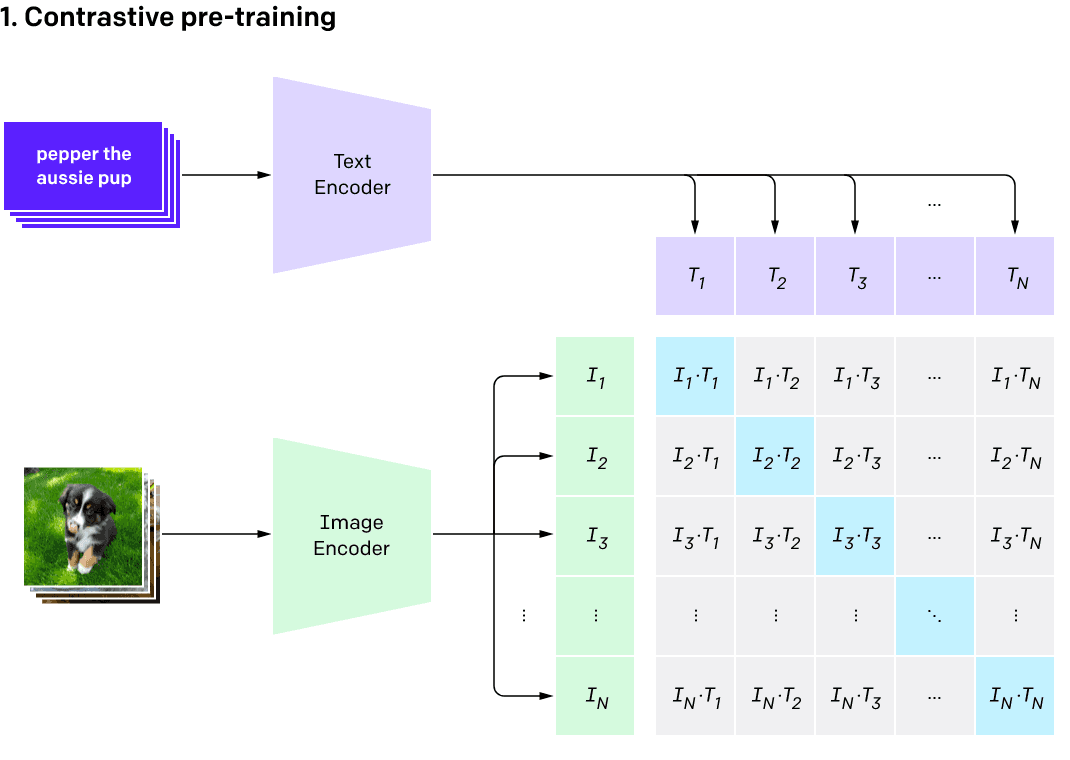
整體流程可以概括為:
- 圖像編碼器將圖像從像素空間(Pixel Space)壓縮到更小維度的潛在空間(Latent Space),捕捉圖像更本質的信息;
- 對潛在空間中的圖片添加噪聲,進行擴散過程(Diffusion Process);
- 通過 CLIP 文本編碼器將輸入的描述語轉換為去噪過程的條件(Conditioning);
- 基於一些條件對圖像進行去噪(Denoising)以獲得生成圖片的潛在表示,去噪步驟可以靈活地以文本、圖像和其他形式為條件(以文本為條件即 text2img、以圖像為條件即 img2img);
- 圖像解碼器通過將圖像從潛在空間轉換回像素空間來生成最終圖像。
工作流示例#
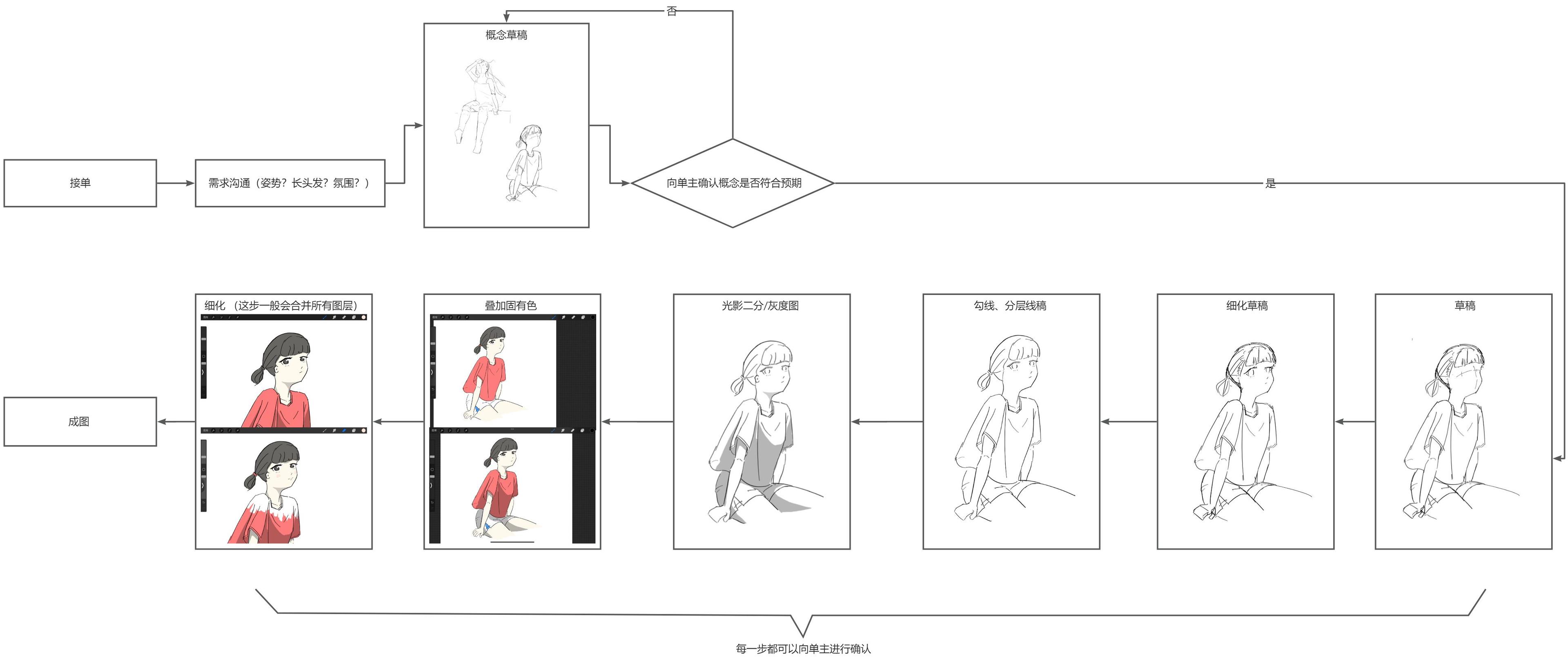
現在我們以這樣一個需求為例:一個人想要一張「坐在天台邊抬頭看著鏡頭的女孩」插畫。(圖片不夠大可以右鍵在新標籤頁中打開)
傳統工作流#
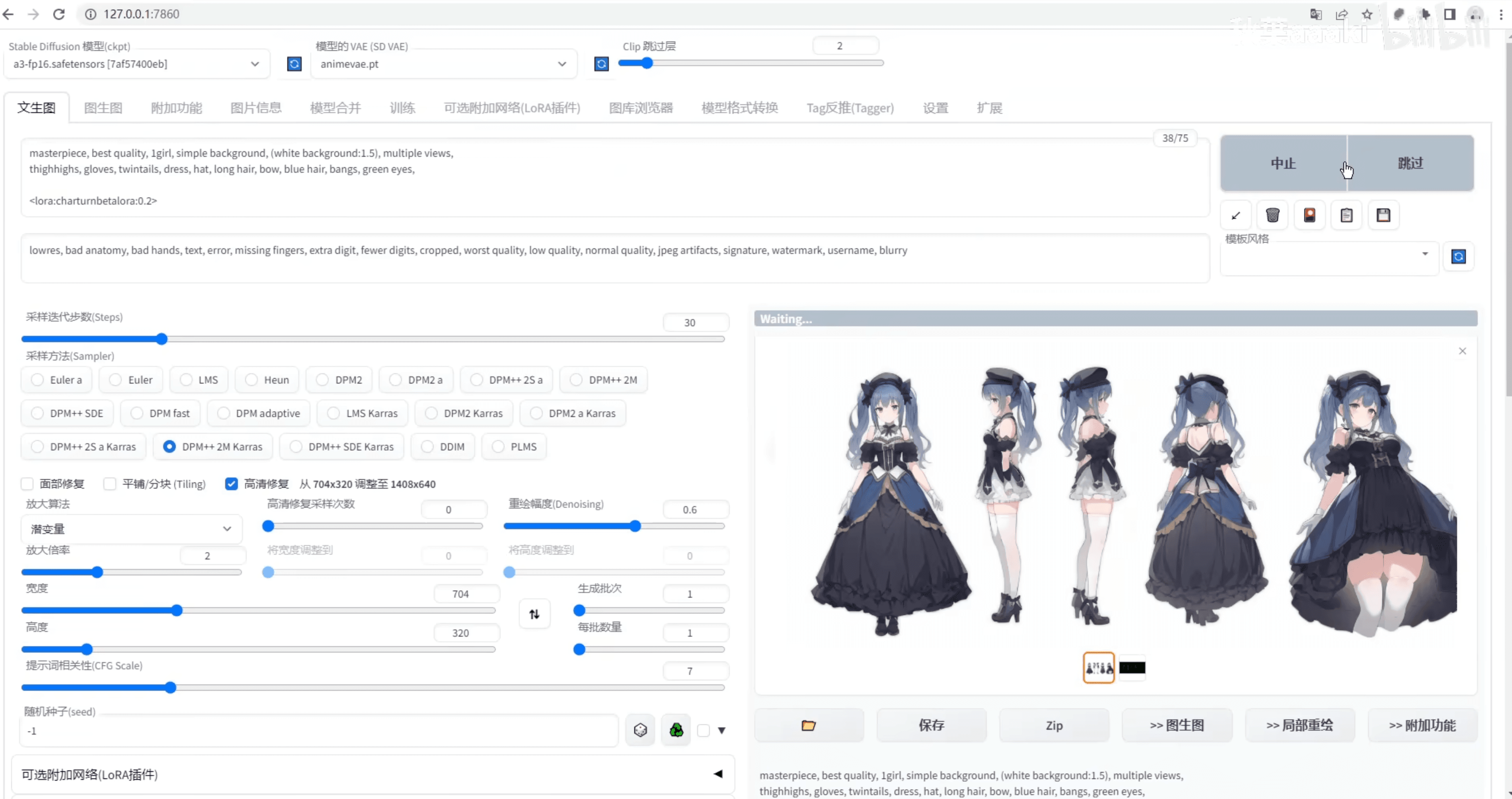
下面則是幾種我用 ai 優化工作流的思路,使用的工具是本地部署的 ai 繪畫最流行的工具 stable-diffusion-webui
批量概念圖工作流#
需求溝通和概念草稿階段能快速生成大量概念圖,讓甲方能提前預選一個它想要的圖。適用於甲方需求不清晰的場景。方向確定後我們根據概念圖進行創作(不是直接改 ai 的圖),返工的幾率大大降低。
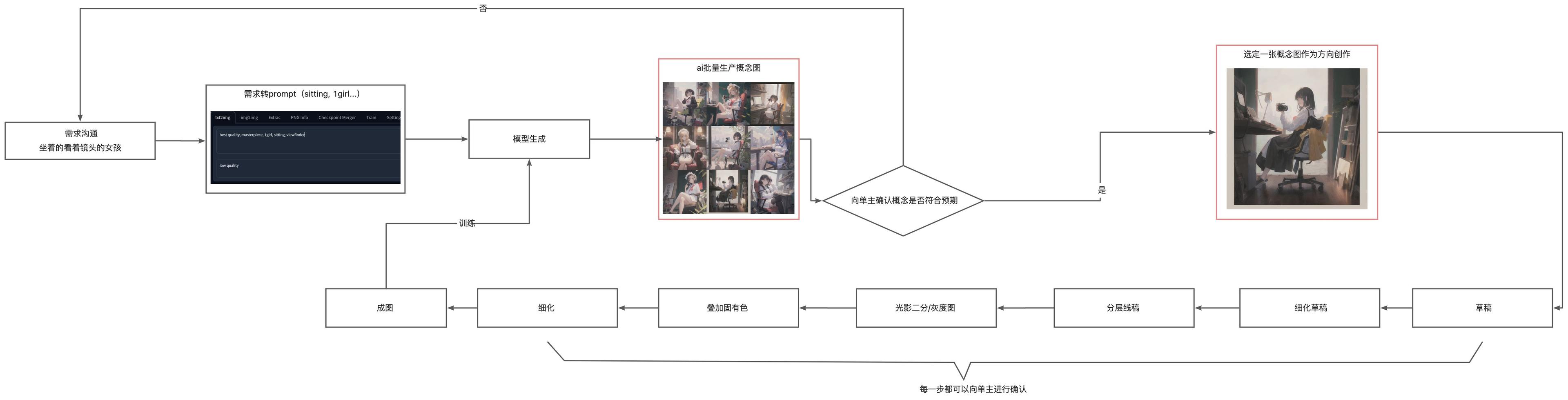
這種方式依然需要創作者親自來創作,但因為成圖都是自己創作的,所以過程中可以很好地訓練屬於自己畫風的模型,用在以後的工作流中。
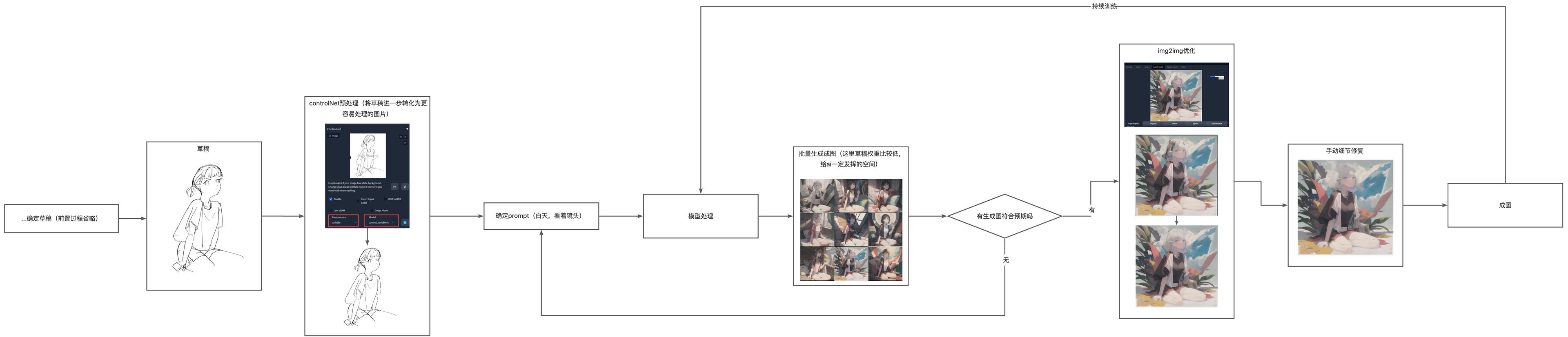
後置 AI 工作流#
將 ai 產出的圖片作為結果的工作流,創作者僅需提供草稿和大致的描述 prompt,讓 ai 來生成圖片,這種方式能用草稿控制整體的框架,但是顏色、氛圍由 ai 來處理。是我個人常用的一種,能在創作和自動化中取得平衡。
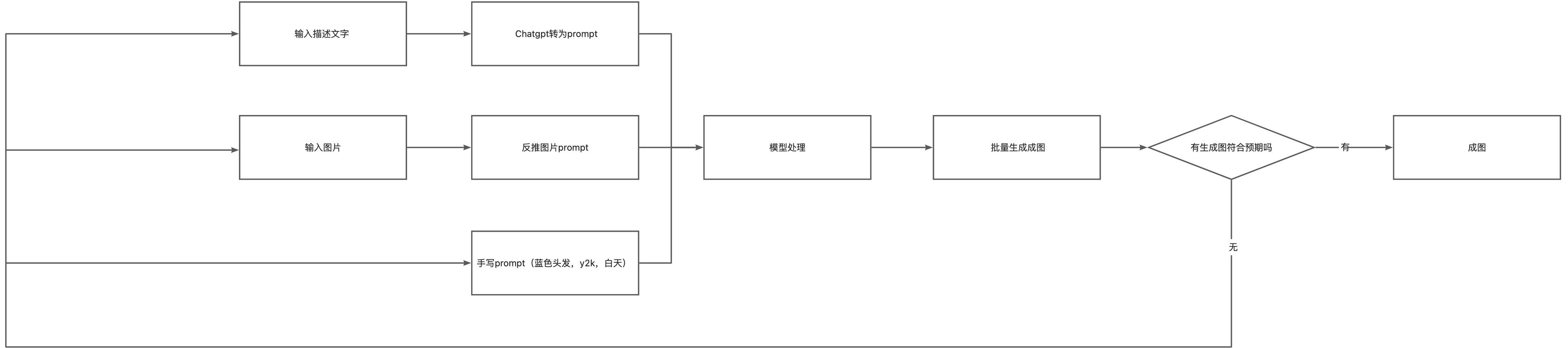
無人工繪圖工作流#
另一種是直接從輸入(可以是描述文字,圖片,或是直接的提示詞)生成圖像的工作流,自動化進一步提高,但我個人不太喜歡這種方式,僅適用非常簡單,要求不高的單子,或者你的模型已經訓練的非常完備了,咸魚中那種自動發貨的 ai 繪圖基本是使用的這種方式。
上面列舉了幾種我之前嘗試過的工作流,但是這幾種工作流也完全可以自己根據場景來裁剪和組合。在你用優質的產出圖片持續訓練自己的模型後,就可以得到一個擁有個人畫風的模型。
這是一組訓練為吉普力工作室畫風的 LORA 模型混合了其他底模產出的頭像,加上了 "flower" 提示詞:












除了這些,stable diffusion 還可以配合其他插件做很多事情,比如一鍵生成三視圖,作為角色設計前期的參考,缺少專業美術資源的項目甚至可以直接就用這些素材。(想象一下你之後花 648 抽的是這個):
※ 當前國內繪圈對於 ai 還是非常敏感,泛興趣社區 lofter 就因為支持了 ai 生成頭像,導致大量站內畫師刪號。
當前缺陷#
二次更改困難#
傳統電子繪畫中,我們會對圖像進行分層,比如人物的翅膀裝飾單獨畫一個圖層,中期就可以隨意更改翅膀的位置,如果要做骨骼動畫,拆件也更容易。但如果我輸入的圖是整圖,ai 也是直接出整圖,這種模式並不匹配傳統的分層邏輯,手動的細節修復工作量並不小,如果甲方要求二次更改插畫中各個物件的位置 / 形狀,因為沒有分層,每一次更改都可能會影響其他的物件,而且改動的筆觸和 ai 本身的畫面不容易融合,整體成本不小。
如果我將手部、身體的線稿單獨給到 ai,讓 ai 進行處理,想讓它產出分層的部件,其他的部件也都重複這個流程,最後將身體、手等 ai 處理後的部件拼接到一起。單獨處理,最後合併,這聽起來是一個更理想的流程,但是每一個部件單獨給到 ai,會讓最後生成的各個部件統一性不足,比較割裂,比如生成的身體中的衣服是一種風格,而生成的手臂的袖子可能會與身體衣服有差異。因為他們是分開處理的而不是統一處理的,ai 無法很好地將他們關聯起來。
產物邏輯統一性缺失#
在工業美術中,不僅要求單張圖的細節達標,同樣要求整個美術資源的統一性,比如人物 A 上有固定的一個 logo 物料,在同系列人物 B 上面也有同樣的物件,這在「邏輯上」是相同的東西,但是目前的模型跑出來很可能兩個人物的 logo 物件是有一定程度的不同的,雖然差異不大,但這在邏輯上是不允許的,logo 形狀只要有些微的差別、或者多了其他元素,就會讓人感覺是兩種物件,無法發揮出「統一物件」本身的作用。



如果是對細節要求不高的插畫,或者前期用來腦暴的概念圖,很適合 ai。
如果是嚴謹的遊戲美術工業中的美術資源,當前 ai 目前在可控性、二次創作能力上還是欠缺了一點。
但按照現在的進化速度,相信在不久的將來上述的問題都會有相應的解法。
珍妮紡織機#
在許多的 aigc 支持者言論中,「珍妮紡織機」常常會被提出來用來類比當前的 aigc,認為 aigc 是下一個珍妮紡織機,能夠改變當前藝術創作的生產關係,將反對者比作是當時打砸機器的「反動紡織工人」。這樣看未免有點太社達主義(即優勝劣汰,強者生存),從產出的產品來看,紡織機產出的衣物和藝術創作者產出的藝術品是兩個維度的東西,前者是更看重產出結果的生活剛需,後者則是更看重創作過程的精神消費品。我們看到梵高的自畫像時能聯想到他悲慘的一生,每一塊顏料的紋理,每一個線條筆觸都是由他親手勾勒,這些種種融合進欣賞體驗中,是 aigc 幾秒產生的畫作從根源上不具備的。
在以前,人作為藝術創作的主體,人這個主體本身也是創作的一部分,創作者和創作過程中的「故事」是產品的一環,為廉價品注入故事是消費升級的手段之一,這個屬性在 aigc 出現後也並不會變,它拉高了最低水平,減少了社會必要勞動時間,但是富人的錢依舊用不完,該升級的消費依舊還是會升級。只是在某些不那麼看中故事性的場景,比如下沉的廉價裝飾畫產品,aigc 的優勢就會非常明顯了。
未來#
ai 其實之前在創作領域已經有很多應用,比如 Photoshop 的抠圖和魔法選區,但現在之所以現在很多人感覺到衝擊,還是因為發現 ai 可以直接產出最終的產品,取代自己的位置,它不再僅僅是一個工具,而是在工作屬性上可能能與自己平起平坐的存在。對於我所了解的一些職業,如漫畫中的勾線助手,動畫中的中割,個人感覺將來基本必定會被取代了。某個評論區截圖,我不保證真實性:

但是我個人仍然覺得 2d 藝術如動畫不會也不應該完全被 ai 取代,引自 b 站 up 主對新海誠訪談中的一段話,關於動畫中的背景圖:



在動畫中哪怕是一帧背景中的一片葉子,也可能因為創作時正好下著雨,於是創作者就在葉子上加了一兩滴露珠。
你學到的每一個概念,你經歷過的每一種情緒,以及你所看到、聽到、聞到、嘗到或觸摸到的一切,都包括關於你身體狀態的數據。你不會以這種方式體驗你的精神生活,但那是‘幕後’發生的事情。
如果之後 ai 動畫普及,你在看一部動畫時,動畫前期都很完美,但突然有一帧 ai 生成了一個不合邏輯的物件,你看到了,就算僅僅是一帧,它也會瞬間將你從 ai 編制的美夢中抽離出來,就像恐怖谷理論一樣。
相比於 2d 藝術,3d 創作因為工業屬性更強,流水線分層更清晰,和 ai 反而相性更好。比如最近出的能一鍵替換人物,自動打光的工具 wonder studio。且它最實用的是可以生成骨骼動畫的中間層,支持二次修改。相比於昂貴的動捕,這種方式的成本會低不少。
但相比以上種種,還是 ai 直接生成攝影作品會更讓我感到恐怖。一個人可以在幾十秒內創造一個不屬於這個世界任何一個地點的空間,打破了攝影的真實性和記錄性。

可能 2030 年,ai 攝影泛濫後,你看到一張風景攝影圖的時候,第一時間不是從心底感嘆這構圖這光影這山這水,而是先去懷疑這是不是 ai 生成的,拍攝的人到底是否當時呼吸著那裡的空氣,感受著那裡的陽光,為當時空間中各種反射光打到視網膜產生的神經信號產生的內啡肽作用下舉起相機,按下快門,定格世界上某個地點某一時刻的某一瞬間。當然,他也可以讓 chagpt 輔助他編造出他是經歷過這些過程最後產出了這張作品。
我們能做些什麼#
作為程序員,我以前經常陷入一個誤區,就是對於某一個領域我必須要從底層學起才能算 “入門”,但是當前的 ai 已經有非常多十分方便的上層應用,如果基礎不足,直接從這些普遍使用的上層開始也未嘗不可,然後利用自己能力去添磚加瓦。比如我對 ai 的基礎非常薄弱,那可以基於現有的服務去訓練微調模型(如 openai 的 tuning model),用在更細分的領域;我只會 curd,我就調用它們的 openapi 去做服務封裝;我只會前端,我就開發一個更好用的 ui 界面;我只會畫畫,我就嘗試用當前已有的能力看如何優化我的工作流提高效率,這些都是不錯的實踐。
結語#
當前人類在某些細分領域看起來已經不及 ai 了,ai 多模態的能力相比之前也取得了不小的進步。但直到現在人腦甚至人體也存在著大量黑盒,chatgpt 力大飛磚展現出的智能也和人腦的實際運行有不小的區別,人腦的效率相比機器依然很高(以 GPT-3.5 為模型的 ChatGPT 模型為例,訓練一次的成本要 460 萬到 500 萬美元。),細分領域方向的 ai 目前看來也比強人工智能方向的 ai 性價比更高,可見的時間內,我們還不需要擔心被完全取代。
但就像需要學會如何與人打交道一樣,將來我們大概率也需要學習如何與 ai 交流合作,如何用更精準的 prompt 向 stable diffusion 描述畫面,如何用更清晰的語句,更合理的誘導向 chatGPT 提問、構建上下文,以便更快的得到想要的結果。
當前人類的多模態、泛化能力依然還是很強大,無法量化的共情、好奇心等也一直在默默地推動著社會向前。我一定程度相信星際穿越中的 “only love and gravity”。理性上,看著天空沒有任何意義,但可能正是第一個仰望星空的猿人的好奇心,讓我們能走到現在。