This article uses the vertical field of painting as a starting point to introduce how AIGC can optimize the current painting workflow. This aims to inspire thoughts on what AIGC can already achieve in another industry that feels distant to me, what new possibilities it may bring, and what we can do about it.
Simple Principles#
Below, I will briefly explain the principles using diffusion models as an example, based on my understanding.
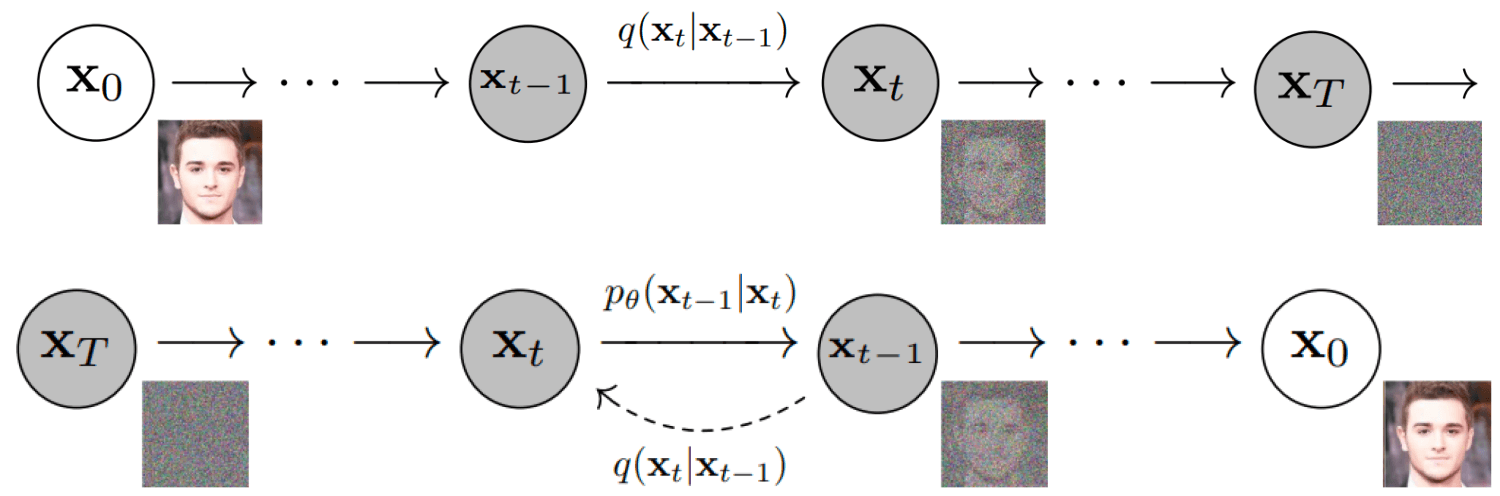
Training Process
We add noise to the original image, gradually turning it into a pure noise image; then we let the AI learn the reverse process, which is how to obtain a high-definition image with information from a noise image. After that, we control this process with conditions (such as descriptive text or images), guiding it on how to iterate to denoise and generate specific graphics.
Latent Space
An image with a resolution of 512x512 is a set of 512 * 512 * 3 numbers. If we directly learn from the image, it means the AI has to process data in 786432 dimensions, which requires high computing power and computer performance. Therefore, we need to compress the information, and the compressed space is called "latent space."
If we have a list of 10,000 people's information and want to find two who might be brothers, if we process each line, we would have to handle 10,000. But if we have a three-dimensional coordinate system representing people's latent space, with three axes for height, weight, and birthday, we can find two adjacent points in this three-dimensional space, which would likely represent similar individuals. This multidimensional information is easier for AI to process.
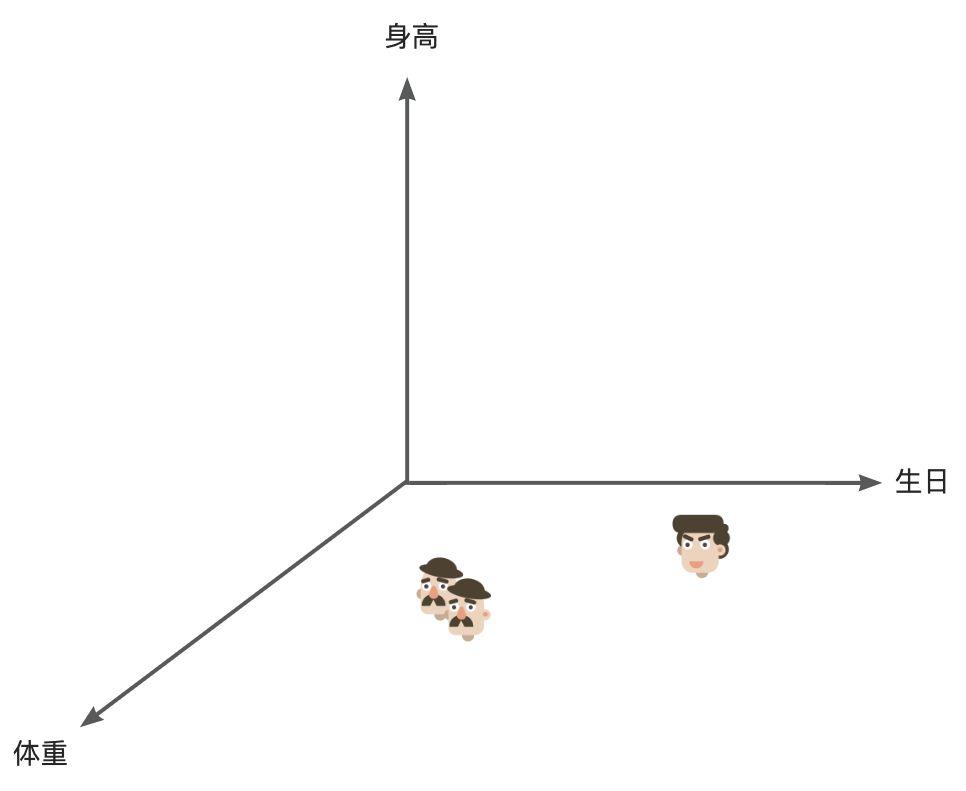
Human cognition works similarly; when recognizing a new category of things, we subconsciously classify features and label them in multiple dimensions. For example, we can easily distinguish between a chair and a table because they are obviously different in terms of volume.
AI can also do the same thing, compressing a vast dataset into many feature dimensions, transforming it into a much smaller "latent space." Thus, finding an image is like searching for a corresponding coordinate point in such a space, which is then processed into an image.
CLIP
When using various online AIGC services, we often utilize the text-to-image functionality. To establish a connection between text and images, AI needs to learn the matching of images and text from a massive amount of "text-image" data. This is what CLIP (Contrastive Language-Image Pre-Training) does.
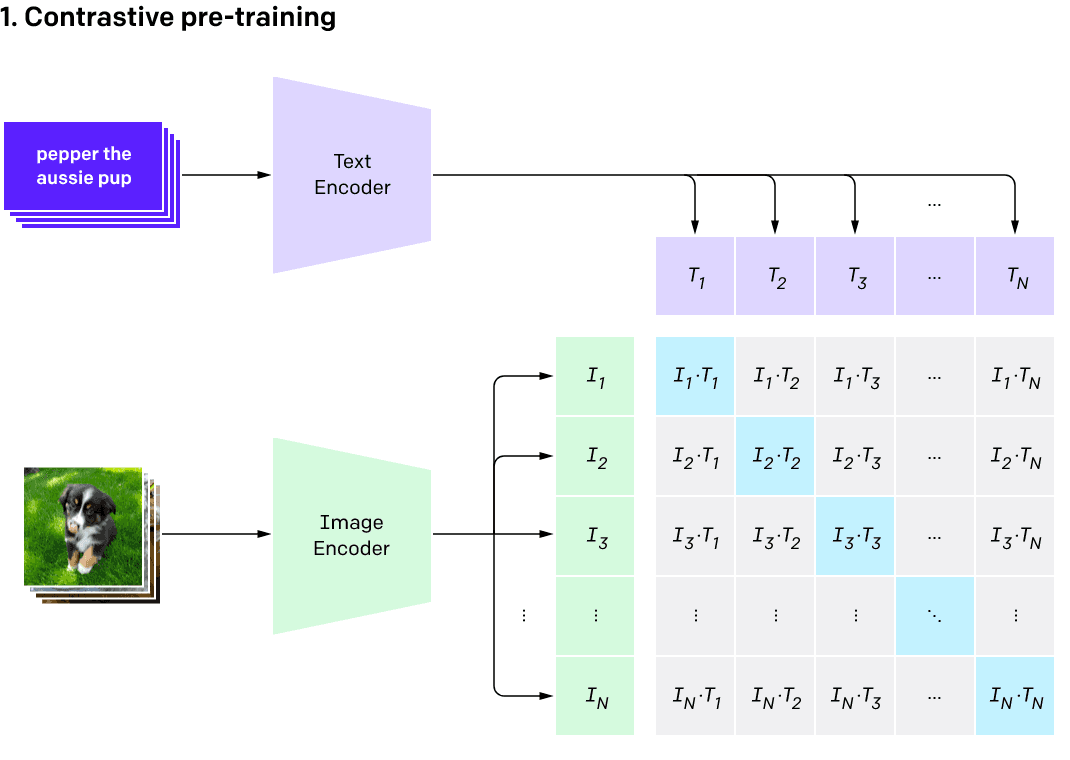
The overall process can be summarized as follows:
- The image encoder compresses the image from pixel space (Pixel Space) to a smaller dimensional latent space (Latent Space), capturing the essential information of the image;
- Noise is added to the images in latent space, undergoing a diffusion process (Diffusion Process);
- The input description is converted into conditions for the denoising process through the CLIP text encoder (Conditioning);
- Based on certain conditions, the image is denoised to obtain the latent representation of the generated image. The denoising steps can flexibly use text, images, and other forms as conditions (text-to-image or image-to-image);
- The image decoder generates the final image by converting the image from latent space back to pixel space.
Workflow Example#
Now let's take a demand as an example: a person wants an illustration of "a girl sitting on the edge of a rooftop looking up at the camera." (If the image is not large enough, you can right-click to open it in a new tab.)
Traditional Workflow#
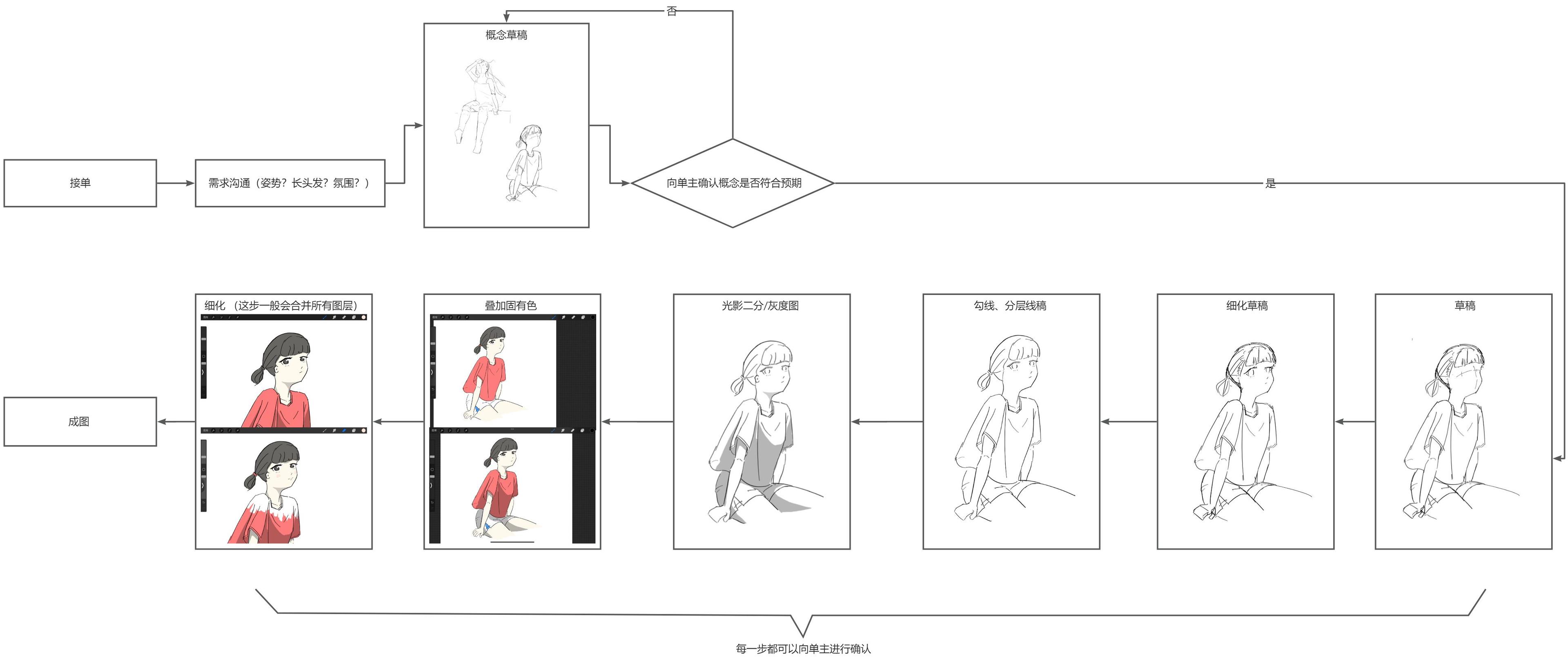
Below are some ideas I have for optimizing workflows using AI, with the tool being the locally deployed AI painting tool, stable-diffusion-webui.
Batch Concept Art Workflow#
In the demand communication and concept draft stage, a large number of concept images can be quickly generated, allowing the client to pre-select an image they want. This is suitable for scenarios where the client's requirements are unclear. Once the direction is determined, we create based on the concept images (not directly modifying AI's images), greatly reducing the chances of rework.
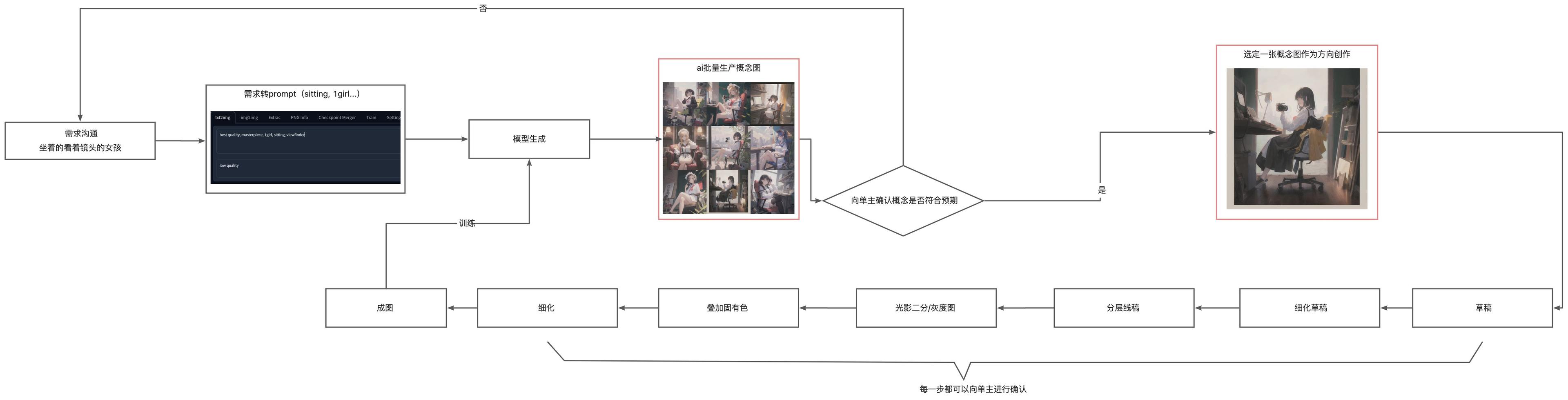
This method still requires the creator to personally create, but since the images are all self-created, it allows for good training of a model that belongs to their own style, which can be used in future workflows.
Post-AI Workflow#
Using AI-generated images as the result of the workflow, the creator only needs to provide a draft and a rough description prompt, allowing AI to generate the image. This method can control the overall framework with the draft, while colors and atmosphere are handled by AI. This is a method I commonly use, achieving a balance between creation and automation.
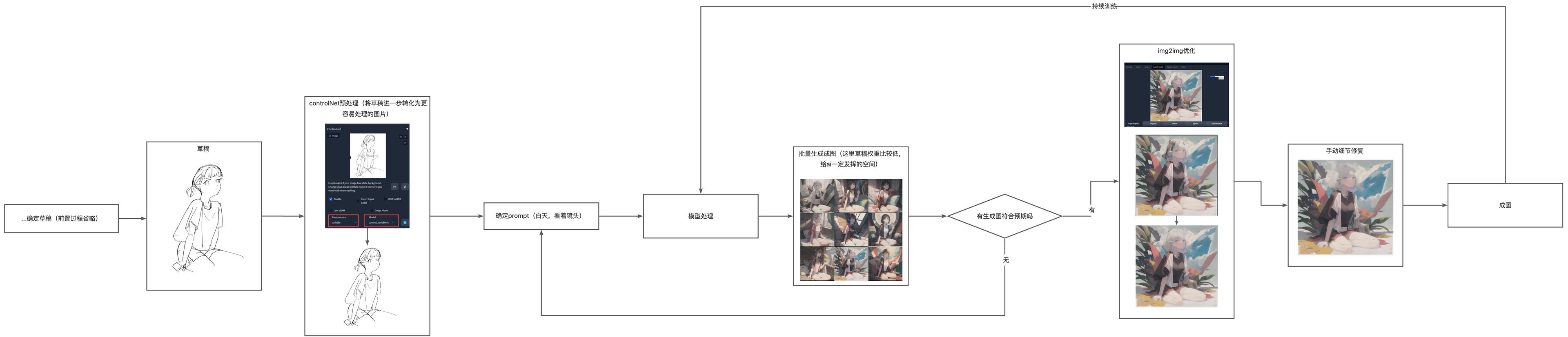
No-Human Drawing Workflow#
Another method is to directly generate images from inputs (which can be descriptive text, images, or direct prompts), further increasing automation. However, I personally do not favor this method, as it is only suitable for very simple, low-demand tasks, or if your model has already been trained very well. The kind of AI drawing that automatically delivers on platforms like Xianyu typically uses this method.
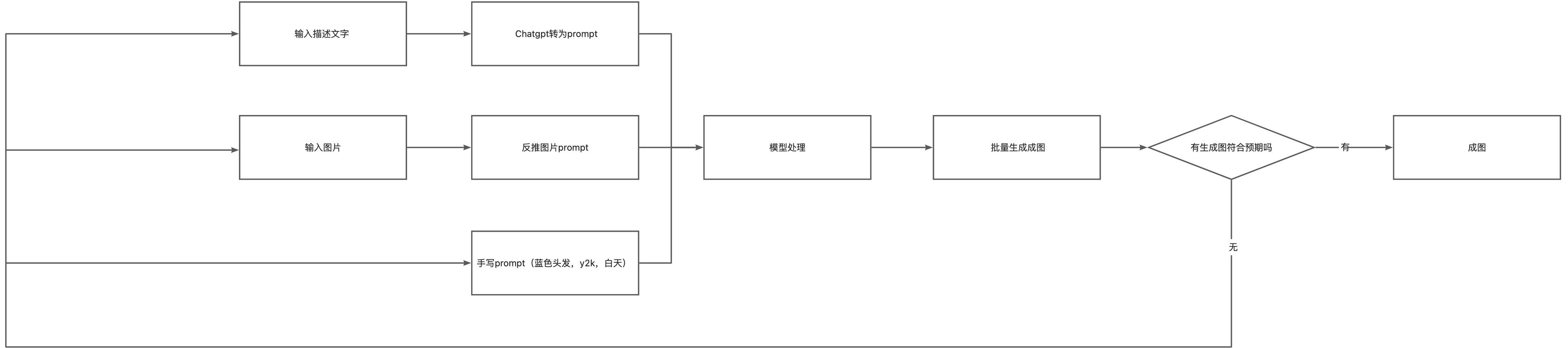
The above lists several workflows I have tried before, but these workflows can also be tailored and combined according to the scenario. After continuously training your model with high-quality output images, you can obtain a model with a personal style.
This is a set of LORA models trained in the style of Studio Ghibli, mixed with other base models to produce portraits, along with the "flower" prompt:












In addition to these, stable diffusion can also work with other plugins to do many things, such as generating three-view images with one click, serving as references for character design in projects lacking professional artistic resources, which can even directly use these materials. (Imagine you might spend 648 later for this):
※ Currently, the domestic painting community is still very sensitive to AI. The interest community Lofter faced a large number of artists deleting their accounts due to supporting AI-generated avatars.
Current Defects#
Difficulty in Secondary Changes#
In traditional digital painting, we layer images, such as drawing a separate layer for a character's wing decorations, allowing for easy repositioning of the wings during the mid-stage. If we want to do skeletal animation, disassembling parts is also easier. However, if the input image is a complete image and the AI directly outputs a complete image, this mode does not match the traditional layering logic. The manual detail repair workload is considerable. If the client requests secondary changes to the positions/shapes of various objects in the illustration, due to the lack of layering, each change may affect other objects, and the brush strokes of the manual changes do not easily blend with the AI-generated image, resulting in significant overall costs.
If I provide the line art of the hands and body separately to the AI for processing, aiming to produce layered components, and repeat this process for other components, finally assembling the AI-processed parts like the body and hands together, this sounds like a more ideal workflow. However, processing each component separately may lead to a lack of uniformity among the generated parts, creating a disjointed appearance. For example, the clothes generated for the body may have one style, while the sleeves of the arms may differ from the body’s clothing. Since they are processed separately rather than uniformly, the AI cannot effectively relate them.
Lack of Logical Consistency in Products#
In industrial art, not only is the detail of a single image required to meet standards, but the overall consistency of the artistic resources is also essential. For example, if character A has a fixed logo material, character B in the same series should also have the same object. While logically these are the same items, the current models may produce logos for the two characters that differ to some extent. Although the differences may be minor, this is not permissible logically. If the logo shape has slight variations or additional elements, it will make people feel they are two different objects, undermining the function of a "unified object."



If the illustration has low detail requirements or is used for brainstorming concept images, AI is very suitable. However, for artistic resources in rigorous game art industries, current AI still lacks controllability and secondary creation capabilities.
But given the current pace of evolution, I believe that solutions to the above problems will emerge in the near future.
The Jenny Loom#
In many AIGC supporters' discussions, the "Jenny Loom" is often mentioned as a comparison to current AIGC, suggesting that AIGC is the next Jenny Loom, capable of changing the production relations of current artistic creation, with opponents likened to the "reactionary textile workers" who smashed machines at that time. This perspective seems a bit too social Darwinist (i.e., survival of the fittest). From the perspective of the products produced, the clothing produced by the loom and the artworks produced by artists are two different dimensions. The former emphasizes the output results as a basic necessity of life, while the latter focuses more on the creative process as a spiritual consumer good. When we see Van Gogh's self-portrait, we can recall his tragic life; every texture of paint and every brushstroke was drawn by his own hand. These elements are integrated into the appreciation experience, which is fundamentally absent from the paintings generated by AIGC in seconds.
In the past, humans were the subjects of artistic creation, and this subject was also part of the creation. The creator and the "story" in the creative process are part of the product. Injecting stories into cheap products is one of the means of consumption upgrading. This attribute will not change with the emergence of AIGC; it raises the minimum level and reduces the socially necessary labor time. However, the rich still have endless money, and the consumption that needs upgrading will still upgrade. It’s just that in some scenarios that do not emphasize storytelling, such as low-cost decorative painting products, the advantages of AIGC will be very obvious.
The Future#
AI has already had many applications in the creative field, such as Photoshop's cutout and magic selection. However, the reason many people feel the impact now is that they have discovered that AI can directly produce final products, replacing their positions. It is no longer just a tool but may exist on equal footing with them in terms of work attributes. For some professions I am familiar with, such as line assistants in comics and in-betweeners in animation, I personally feel that they will likely be replaced in the future. A screenshot from a comment section, which I cannot guarantee its authenticity:

However, I still believe that 2D art, such as animation, should not and cannot be completely replaced by AI. Quoting a statement from a Bilibili UP master during an interview with Makoto Shinkai about background images in animation:



In animation, even a single leaf in the background of a frame may have droplets added by the creator because it was raining during the creation process.
Every concept you learn, every emotion you experience, and everything you see, hear, smell, taste, or touch includes data about your bodily state. You may not experience your mental life this way, but that is what happens 'behind the scenes.'
If AI animation becomes widespread in the future, when watching an animation, if the early parts are perfect but suddenly one frame generates an illogical object, and you see it, even if it’s just one frame, it will instantly pull you out of the beautiful dream crafted by AI, much like the uncanny valley theory.
Compared to 2D art, 3D creation has a stronger industrial attribute, clearer assembly line layering, and is more compatible with AI. For example, the recently released tool Wonder Studio can replace characters with one click and automatically light them. Its most practical feature is generating intermediate layers for skeletal animation, supporting secondary modifications. Compared to expensive motion capture, this method is much more cost-effective.
However, compared to all of the above, AI directly generating photographic works terrifies me even more. A person can create a space that does not belong to any location in this world in just a few seconds, breaking the authenticity and record-keeping nature of photography.

Perhaps by 2030, after the proliferation of AI photography, when you see a landscape photograph, your first thought may not be to marvel at the composition, lighting, mountains, and water, but to question whether it was AI-generated, whether the person who took it was breathing the air there, feeling the sunlight, and capturing the moment of a specific place in time under the effects of the neural signals generated by various reflected lights hitting their retina. Of course, they could also have ChatGPT assist them in fabricating a story about having experienced these processes before producing this work.
What Can We Do?#
As a programmer, I used to often fall into a misconception that I must start from the bottom in a particular field to be considered "beginner." However, current AI has many very convenient upper-level applications. If the foundation is insufficient, starting directly from these commonly used upper levels is also a viable option, and then using one's abilities to contribute. For example, if my understanding of AI is very shallow, I can train and fine-tune models based on existing services (like OpenAI's tuning model) for more specialized fields; if I only know CRUD, I can call their OpenAPI to do service encapsulation; if I only know front-end, I can develop a better UI interface; if I only know how to draw, I can try to optimize my workflow and improve efficiency with my current abilities. These are all good practices.
Conclusion#
Currently, humans seem to be outperformed by AI in certain specialized fields, and AI's multimodal capabilities have also made significant progress compared to before. However, even now, the human brain and body still contain many black boxes. The intelligence demonstrated by ChatGPT is quite different from the actual functioning of the human brain. The efficiency of the human brain remains high compared to machines (for example, training the ChatGPT model based on GPT-3.5 costs between 4.6 million to 5 million dollars). Currently, AI in specialized fields seems to offer better cost-effectiveness than AI in strong artificial intelligence directions. In the foreseeable future, we do not need to worry about being completely replaced.
But just as we need to learn how to interact with people, we will likely need to learn how to communicate and collaborate with AI in the future, how to describe images to Stable Diffusion with more precise prompts, and how to ask clearer questions and construct context with ChatGPT to obtain desired results more quickly.
The current human multimodal and generalization capabilities are still very powerful, and the unquantifiable empathy, curiosity, and other traits continue to silently drive society forward. I somewhat believe in the "only love and gravity" from Interstellar. Rationally, looking at the sky may seem meaningless, but perhaps it was the curiosity of the first ape to gaze at the stars that has brought us to where we are now.